
墨芯完成智谱大模型适配黄金认证,助推国产算力商业化进程
 2023-11-27
2023-11-27
在推动大模型算力量级提升的道路上,稀疏计算引领者墨芯人工智能(以下简称“墨芯”)再次迈出重要的一步。近日,墨芯旗下产品S30计算卡经过智谱AI内部专家的严格测评,荣获黄金级别认证,充分显示了其与智谱AI(以下简称“智谱”)的ChatGLM2-6B大模型在推理与微调方面的高度兼容性和卓越适配能力。

除了上述已经成功适配的开源大模型ChatGLM2-6B外,墨芯正通过基于S30计算卡的定制化算力为智谱提供一体化解决方案,同时也积极参与到智谱其他闭源商业大模型的兼容性适配中。这一过程也加速了智谱AI大模型的商业化步伐。
墨芯的助力,不仅是对智谱现有AI产品矩阵的算力技术加持,更是对其未来AI技术应用领域落地的一次积极探索。通过这种合作,墨芯和智谱AI共同推动了其大模型技术的商业化进程,加快了其在多个行业中的实际应用和普及。墨芯的S30计算卡作为这一合作的关键组成部分,其强大的算力和高效的适配能力不仅加速了智谱AI大模型的开发和部署,也为之后在更多领域的合作提供了坚实的基础,进一步推动了国产大模型的广泛应用和行业渗透。

通过本次认证的S30计算卡搭载墨芯首颗Antoum®️芯片,以其高达32倍稀疏率的强劲AI算力,专注服务与数据中心AI推理的多元需求。其应用领域覆盖了互联网、通信、智慧城市建设、生命科学、自动驾驶等关键行业,体现了其广泛的适用性和灵活性。
墨芯的双稀疏算法和Antoum®架构的创新,使S30在同行业产品中处于领先地位,更显著优化了客户的总拥有成本(TCO)。
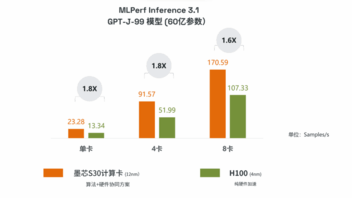
S30计算卡在行业内以其卓越的推理加速性能始终保持领先。此前,在9月举办的最新一届的全球权威测评MLPerf Inference 3.1推理评测中,墨芯S30计算卡,以其无与伦比的性能,在处理GPT-J(60亿参数)大模型推理任务时,无论是单卡还是多卡配置,均力压群雄,荣登榜首。这是墨芯连续第三次在MLPerf推理评测中取得领先成绩,进一步夯实其在AI算力领域的领导地位。
ChatGLM2-6B模型由智谱AI与清华大学KEG实验室共同研发,是一款功能强大的开源中英双语对话模型。其在沿袭了初代模型的流畅对话和低部署难度的基础上,进一步提升了推理速度和降低显存占用,整体性能更加出色。
墨芯获得智谱ChatGLM2-6B模型黄金认证证书
除了上述已经成功适配的开源大模型ChatGLM2-6B外,墨芯正通过基于S30计算卡的定制化算力为智谱提供一体化解决方案,同时也积极参与到智谱其他闭源商业大模型的兼容性适配中。这一过程也加速了智谱AI大模型的商业化步伐。
墨芯的助力,不仅是对智谱现有AI产品矩阵的算力技术加持,更是对其未来AI技术应用领域落地的一次积极探索。通过这种合作,墨芯和智谱AI共同推动了其大模型技术的商业化进程,加快了其在多个行业中的实际应用和普及。墨芯的S30计算卡作为这一合作的关键组成部分,其强大的算力和高效的适配能力不仅加速了智谱AI大模型的开发和部署,也为之后在更多领域的合作提供了坚实的基础,进一步推动了国产大模型的广泛应用和行业渗透。
墨芯S30计算卡
通过本次认证的S30计算卡搭载墨芯首颗Antoum®️芯片,以其高达32倍稀疏率的强劲AI算力,专注服务与数据中心AI推理的多元需求。其应用领域覆盖了互联网、通信、智慧城市建设、生命科学、自动驾驶等关键行业,体现了其广泛的适用性和灵活性。
墨芯的双稀疏算法和Antoum®架构的创新,使S30在同行业产品中处于领先地位,更显著优化了客户的总拥有成本(TCO)。
S30计算卡在行业内以其卓越的推理加速性能始终保持领先。此前,在9月举办的最新一届的全球权威测评MLPerf Inference 3.1推理评测中,墨芯S30计算卡,以其无与伦比的性能,在处理GPT-J(60亿参数)大模型推理任务时,无论是单卡还是多卡配置,均力压群雄,荣登榜首。这是墨芯连续第三次在MLPerf推理评测中取得领先成绩,进一步夯实其在AI算力领域的领导地位。
墨芯S30计算卡在GPT-J-99模型中的性能表现
ChatGLM2-6B模型由智谱AI与清华大学KEG实验室共同研发,是一款功能强大的开源中英双语对话模型。其在沿袭了初代模型的流畅对话和低部署难度的基础上,进一步提升了推理速度和降低显存占用,整体性能更加出色。
S30计算卡的黄金认证,不仅是其技术实力的显著证明,更是墨芯赋能智谱大模型商业化进程的关键一环,不仅证实了S30计算卡在运行智谱ChatGLM2-6B大模型时的稳定性和高吞吐能力,也标志着墨芯与智谱在共同推进大模型技术发展和生态建设方面的成功合作。未来,墨芯人工智能将与智谱AI在更多领域展开广阔合作,共同致力于推动国产AI大模型生态圈的协同进步与创新。


 粤ICP备2021128059号
粤ICP备2021128059号